
Chapter 2: PRECISION 3: Here Comes The "Judge"
Posted by Andrew Davidson on November 7, 2023
Now that we have an indisputable correct answer, sampled dozens of times per second throughout every ride, it’s up to the development team to create an algorithm that replicates the gyro reading using just the accelerometer. The developer then takes their new cadence algorithm and runs it against every pre-recorded ride in the Library to see how closely it matches the gyro. The result is an objective measurement like, “this version of the algorithm scores 97.56% versus the theoretically perfect output” and lets us directly compare completely different approaches and ideas. We call this system the “Judge.”
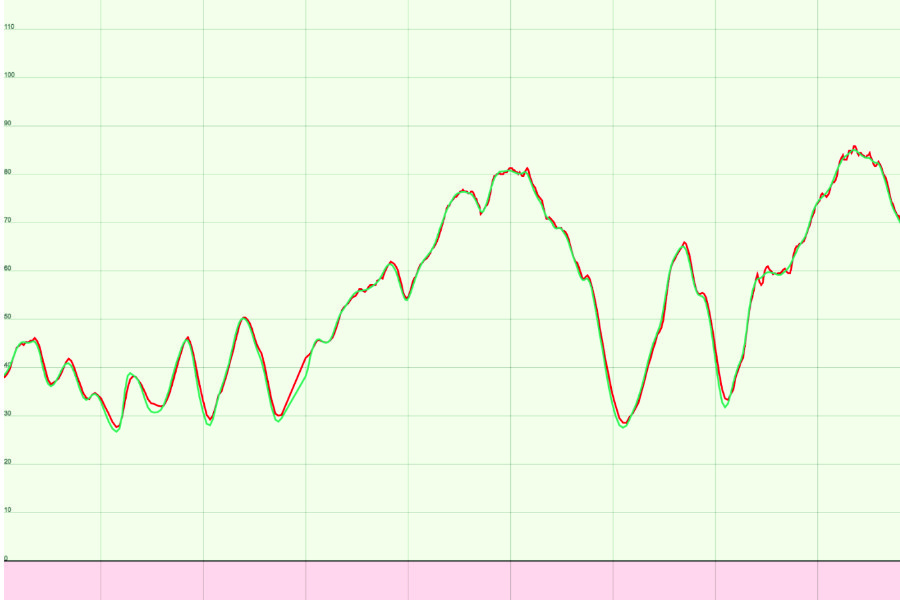
Above: The “right” cadence answer (green) and the cadence output (red) from a run of the P3 1.2 Cadence Algorithm
In the past, the way we’d do this type of development is to make some algorithm changes, go ride it, and then ask the rider to report back on where it was good and bad. The rider is a key link in the system and would need to monitor what’s happening with the power meter while riding. This method can obviously prove difficult, as you can’t always duplicate the route and ride effort in the exact same way. It’s also a huge advantage for a developer to get instant objective feedback on their ideas. Where a rider might take several hours to complete a test, with the potential to miss things, the Judge can run hundreds of rides from the library in minutes and provide an objective, numerical score on the quality of the algorithm. If we, as a team, decide to emphasize responsiveness, then we add that preference into the Judge’s scoring system. If we want to emphasize quick startup, then we have the Judge penalize algorithms with slow startups.

Above: Judge output for some of the test files in our test library. It’s like sports but much more boring.
Test-Driven Development: No Recurring Zombie Bugs.
By having a large ride library and objective scoring, we can make sure we are continuously stepping forwards in terms of quality. Day to day as a developers, we target the worst-performing ride, fix any underperformance that occurs, and rerun the Judge. If the score improves, then we commit the code to save the progress and repeat on the next worst-performing log. After steady development, focusing on improving how close we’re getting to the “right answer,” over days, weeks, and months, we end up with a robust, all-conditions cadence algorithm that matches the gyro while using up to 3x less power.

In addition to the Judge’s scoring system ensuring we’re continuously ratcheting quality up, we can flag every critical bug we find into tests, and stop the creation of firmware that fails those tests. For example, one firmware failed to turn on when you spun the crank backwards, so we wrote a test that spun our virtual crank backwards, checked that it turned on, then made sure we were never able to build a new firmware that failed the test. Another version failed to respond to the accelerometer after 65536sec of on-time. It turned out to be a power meter version of Y2K: one calculation out of hundreds didn’t support large numbers, so we wrote a test that required identical performance after adding 65536sec to all timestamps and added it to the “must pass” list.

This was an immense step forward over past product development: In the past, where each firmware iteration would need to be physically test-ridden, it would sometimes reveal that an old bug had returned from the dead (Zombie Bug), which wasn’t particularly time efficient process. For example, an attempt to improve high-cadence performance might hurt low-cadence performance, or vice-versa. By having the Judge ensure that general performance was always improving and the test suite ensuring no critical bugs were allowed to reappear, each new firmware release brought significant steps forward and rarely any steps back!
In the next chapter we ask the question, “human developers can be slow… can we help them out?”

